第3回 翻訳設定と訳文出力 【演習】
第3回 翻訳設定と訳文出力 【演習】 |
前編集の方法 |
|
| PC-Transer EJでは、原文を対訳エディタに読み込む前に、制御コードを入力することによって、原文の前編集をすることができます。 | |
制御コードには以下のようなものがあります。
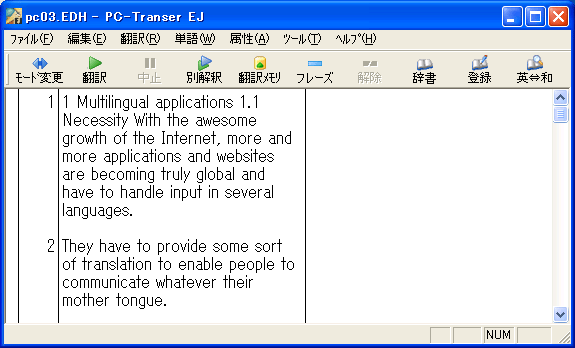
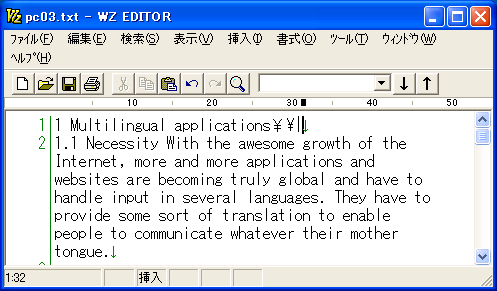
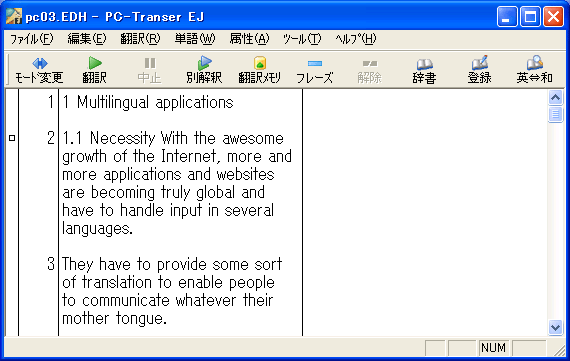
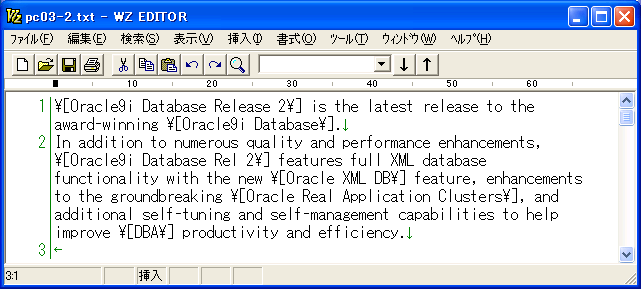
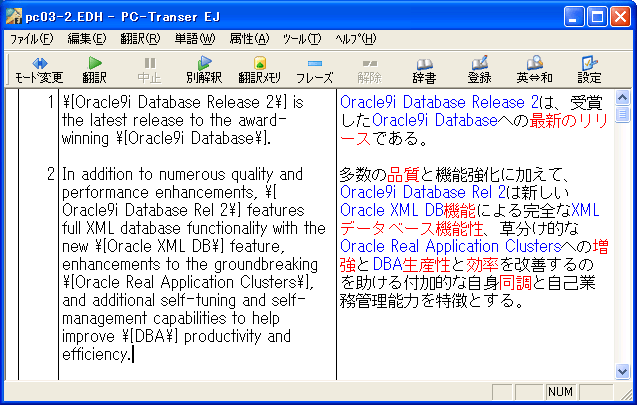
★2と3は対訳エディタに読み込んでからも使用できます。エディタの検索・置換機能をうまく使って一気にこれらの制御コードを付加してしまえば訳文修正の手間が少しは軽減されます。「ユーザ前処理して読み込み」スクリプトで利用してみるのも良いかもしれません。それには原文をじっくり観察することも必要になってきます。 1. 文の強制分割分割したいところに \| と入力します。対訳エディタに読み込むと、この記号のところで強制的に別のセルに分割されます。ピリオドなどの文末記号がついていない文は、次の文とつながってしまうことが多いので事前にこの記号を入力しておくと、対訳エディタに読み込んでから一々チェックする手間が省けます。見出しや箇条書きの項目などに使用すると効果があります。 (図1)のように項目1の行末にピリオドが無い場合、PC-Transerで開くと(図2)のように次の文と繋がって一つのセルに入ってしまいます。 (図1)(図3)のように、強制分割記号(\| )を挿入してからPC-Transerで開くと(図4)のようにきちんと分割されます。 (図3)
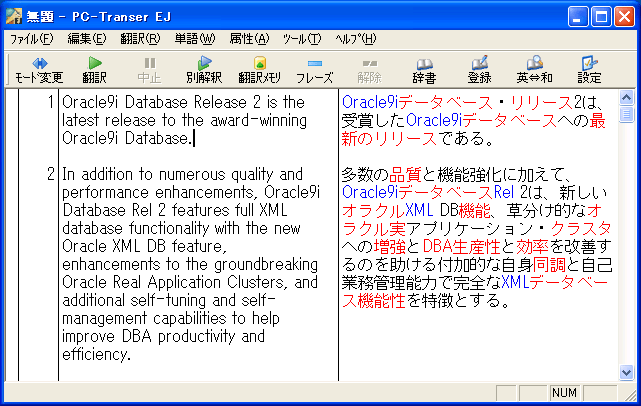
2. 無翻訳指定製品名、固有名詞など訳す必要のないものは \[ と \] で挟みます。無翻訳指定された部分は名詞として処理されますので、未知語の状態にしておくよりも構文解析の負担が減り、訳文の質が高まります。 未知語リストを出力すると、リストアップされるのはほとんどが固有名詞や製品名などでしょう。そのリストをユーザ辞書に登録してもいいのですが、無翻訳指定してしまうという手もあります。 (図5)はコンピュータ専用語辞書を設定してそのまま翻訳したものです。 (図5)テキスト・エディタ上で原文に無翻訳指定の記号を入力しました。(図6) (図6)このファイルをPC-Transrに読み込んで翻訳しました。(図7) 文番号2の訳文は(図5)とかなり違っています。また、全体にこちらの方が読みやすくなっています。 (図7) 3. 構文マーク要するにフレーズ指定です。\{ と \} で挟まれた部分がフレーズとして翻訳されます。特に前置詞句の係り受けの指定や、等位接続詞で繋がれた語句の結びつきの範囲を指定すると効果的です。 (図8)をご覧下さい。 文番号1は、そのまま出力。 文番号2は、\{the threat of a smallpox attack by terrorists\} と構文マークをつけて出力。 文番号3は、文番号2と同じ個所をフレーズ指定して出力。 ★構文マークをつけるのもフレーズ指定するのも効果は同じです。 (図8) |
|
| 前編集は必ずしなくてはならないわけではありませんが、出力結果の質を高めるために有効なことが多いので、試してみる価値はあります。 | |
| 月刊『eとらんす』 2004年1月号連動 Copyright© 2003 Babel K.K. All Rights Reserved. |